后LLM时代:多模态GUI智能体技术如何改变人机交互与社会价值
tokenpocket钱包官网下载 2025年2月12日 18:09:16 tp钱包app下载 107

技术突破:实现“所见即所得”决策

研究团队对Encoder-Decoder的多模态结构进行了训练,这个结构规模相当庞大,达到了1B。他们采用了BLIP2视觉编码器和FLAN-Alpaca语言模型。团队通过分析用户的目标、历史操作以及当前的屏幕截图,成功实现了动作的判断。这种做法让用户看到了即得到了想要的结果,决策即变成了控制。这一创新显著提升了操作效率,特别是在操作复杂的软件时,智能体能够做出精确的决策,大大降低了人为错误的发生。
以往,达成目标需要逐个手动试验。如今,借助这项技术,智能体能迅速且精确地做出判断。这就像身边始终有一位经验丰富的助手在协助,显著减少了用户在时间和精力上的投入。
闭源模型潜力:零样本执行初现
闭源模型技术中,GPT-4V、Gemini-1.5-Pro等高级多模态大模型已能不依赖样本独立运行。即便没有特定样本的培训,它们在图形用户界面操作方面也有一定表现。然而,这些模型并非毫无瑕疵。研究表明,例如GPT-4V在处理web agent任务时,尽管能设计出合理的自然语言行为策略,但在实际应用中执行这些策略的能力较弱。这就像一个人虽然能提出很好的计划,但在执行时却显得有些力不从心。
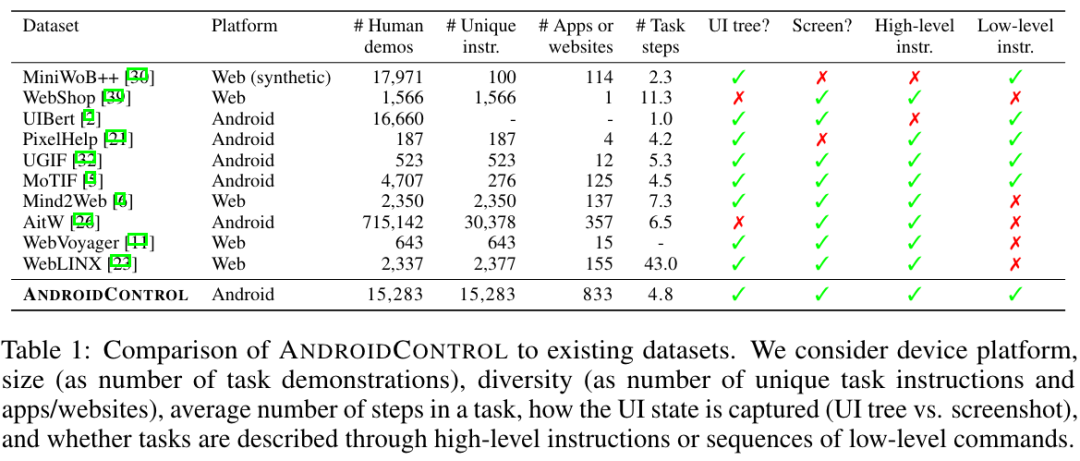
研究者对这一现象进行了深入探究,详细剖析了Prompt的巧妙构造、输入环境的改善以及多个智能体间的协作等多方面内容。他们期望能更深入地挖掘闭源模型在图形用户界面操作上的潜力,从而使其在实际应用中发挥更大效用。
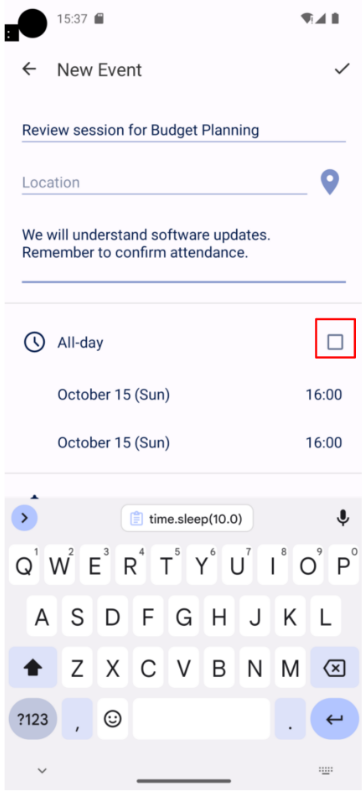
预训练任务:提升专业知识能力
预训练任务主要针对交互数据和标注的单界面数据。经过GUI grounding、GUI VQA等训练,智能体在GUI领域的知识和技能得到了加强。这些数据相当于智能体的知识库,使它在遇到各种GUI场景时,能够采用更多应对策略。
经过训练,智能体在操作专业软件的图形界面时理解更精准,对界面元素及其操作方法掌握得更加熟练。这样的训练让智能体在GUI领域拥有了丰富的经验,使用起来更加自如,帮助用户轻松应对GUI操作的挑战。
模型层面挑战:处理复杂界面元素
设计模型时,我们需要构建新的架构和技术。这样做是为了提升识别和解析图形用户界面及其组件的能力。软件界面越来越复杂,元素种类繁多,布局变化不定,现有模型在面对这些挑战时,往往显得力不从心。
大型游戏的操作界面相当繁杂,其中包含众多功能键和提示信息。这样的界面,现有模型可能难以完全把握各元素间的逻辑联系。为此,研究者们正努力解决一个难题:如何在模型训练初期就提升其应对复杂情况的能力。他们通过持续改进模型结构和训练方式,希望模型在处理复杂的图形用户界面时能表现出更佳的性能。
长远发展目标:集成环境感知能力
长远来看,多模态基座模型需具备对周遭环境的感知与解读能力。训练数据与策略不断优化,模型不应仅限于现有任务,还应拓宽其感知与解读的环境领域。这相当于为智能体增添了灵敏的“感官”,使其能迅速适应各种环境变动。

模型在使用各种软件或设备时,能够自动识别并调整至适宜的环境,从而作出更恰当的选择。若这种多模态基础模型将来能够拥有这样的功能,那么它将在众多领域发挥显著作用,并为用户带来更加高效和智能的使用体验。
评估演变历程:从简单到复杂的跨越
移动端GUI智能体的评估过程,起初是预测单一动作,后来逐渐发展到执行完整任务。起初,这种智能体仅适用于特定分布的任务,而现在它已经能够应用于更广泛的通用任务,并且在多个应用程序以及不同平台(包括移动和PC端)上展现了更强的适应性。起初,由于测试环境的限制,研究者们主要依赖人类标注的静态GUI操作序列数据集。然而,现在的评估方法已经变得更加全面和复杂。
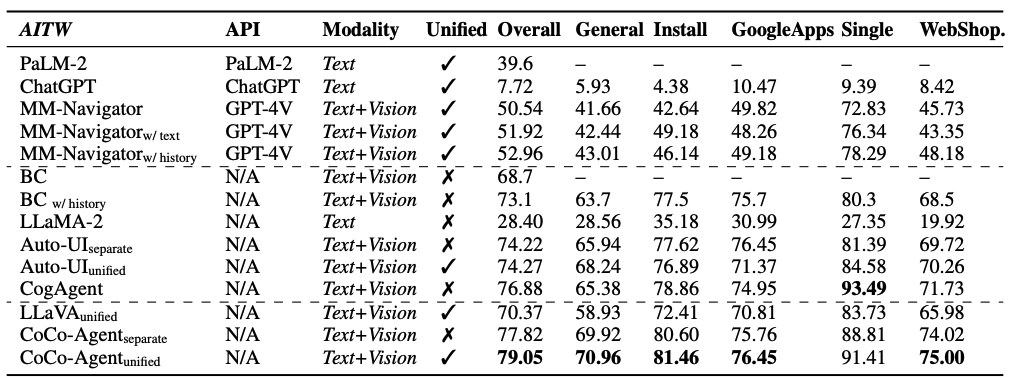
应用软件发展迅速,因此这种评估方法的改变显得尤为重要。这使得移动设备的图形用户界面智能体持续进步,以适应用户需求和应用环境的持续变化。例如,用户期待智能体能在多个应用间自如切换,执行复杂任务,这无疑对智能体的泛化能力和跨平台操作能力提出了更高要求。对于移动端GUI智能体在跨平台操作方面的未来发展,您有何见解?欢迎留言、点赞并转发本文。