Google TPU技术解析:如何实现15-30倍性能提升与30-80倍效率飞跃
tokenpocket钱包官网下载 2025年4月11日 12:18:56 tokenpocket钱包官网下载 170
比特派钱包2025官网下载:bit114.app,bit115.app,btp1.app,btp2.app,btp3.app,btbtptptpie.tu5223.cn
刚开始是否还在为数据处理的缓慢速度和计算能力不足而感到困扰?一旦尝试了Google TPU,你将深刻体验到它带来的计算革新所带来的震撼。

TPU卓越性能提升
TPU的性能相比之前的CPU和GPU有了大幅提高。它能达到15至30倍的性能增长,并且效率(即性能与能耗的比例)提高了30至80倍。以谷歌的搜索、街景、照片和翻译等服务为例,利用TPU加速神经网络运算,处理速度明显加快。数据中心运行时,TPU表现非凡,极大地加快了智能服务的响应效率。
TPU极大提升了效率,这一点极为关键。它不仅降低了能源使用,而且更符合环保要求。与CPU和GPU相比,TPU在执行相同任务时,电力消耗大幅减少。这不仅能减少成本,而且与当前的环保理念相吻合。在处理大量数据计算时,TPU的节能效果会逐渐显现,产生的经济效益非常明显。

快速的设计与部署
从设计开始,经过验证和构建,直至在数据中心部署,TPU的全过程仅需15个月。这种速度在芯片领域实属少见。这充分展示了谷歌在技术领域的卓越实力和开发流程的极高效率。一般而言,芯片的研发可能需要数年时间,但TPU却能快速完成,及时投入使用。

谷歌为了快速将TPU部署到现有服务器,特别设计了这款芯片作为外部扩展加速器,并可直接插入SATA硬盘插槽使用。这种设计巧妙地避开了大规模更换服务器硬件的麻烦,既减少了成本,又节省了时间。因此,TPU能在数据中心迅速投入运作,为各种应用提供强大的计算支持。
神经网络计算简介

在神经网络运算中,复杂结构中的矩阵乘法运算常常非常繁重。了解这一特性,对深入理解TPU的设计思想十分关键。以图像识别为例,这种运算不仅频繁,而且需要处理大量数据,这对传统的CPU和GPU来说,无疑是一项艰巨的任务。
谷歌采用了量化算法来进行整数运算,以此替代了在CPU或GPU上进行的32位或16位浮点运算。这一举措是优化的起点,能显著降低预测成本和内存使用。比如,Inception图像识别模型在应用量化技术后,其体积从91MB缩小到23MB,体积减少了四分之三,更加适合在移动和嵌入式设备上应用。

广泛适用的设计目标
TPU并非只针对单一神经网络设计,它实际上能够增强多种模型的性能。它内置了十几项专门为神经网络推理设计的高级指令,这些指令用于指导MUX、UB和AU的运算。正因如此,TPU在众多领域得到了广泛应用,涵盖了图像识别、语音识别以及自然语言处理等多个方面。

TPU集成了神经网络的关键计算技术,可用于多种神经网络模型的编程。它具备较强的适应性 https://www.ythnjck.com,能够满足不同算法和模型的要求。人工智能领域不断取得进展,新模型和算法不断涌现,TPU的设计特性保证了其持续领先的地位。
高效的运算模式
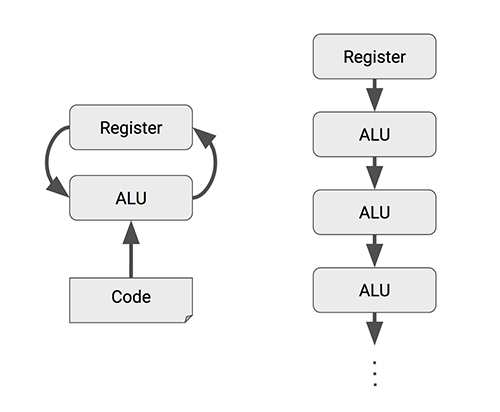
传统CPU在处理大规模矩阵运算时速度较慢,即便主频达到千兆赫兹,仍需多个标量运算步骤。但使用矢量运算能大幅提高效率,GPU的流处理器作为高效的向量处理器,一个时钟周期内就能完成数百到数千次运算。这种差异清楚地显示了TPU在高效运算方面的明显优势。
TPU的MXU是一种矩阵处理器,能在单个时钟周期内完成数十万次运算,主要处理矩阵运算。其性能远超CPU和GPU,为大规模数据的矩阵计算提供了有力保障。在实际应用中,MXU能大幅缩短计算时间,有效加快人工智能任务的处理速度。
单线程芯片的优势

TPU与CPU和GPU有区别,它是一种专门设计的芯片,只能进行单线程处理,不包括缓存、分支预测和多任务处理等复杂功能。CPU和GPU为了提高各种任务的执行速度,内部结构复杂,行为难以预测。但TPU专注于单一任务,因此在神经网络计算上效率更高。
以MLP0为例,它的延迟低于7毫秒。TPU的吞吐量比CPU和GPU多出15到30倍。这说明TPU在处理速度上明显领先。在实际应用中,高吞吐量意味着工作可以更快完成,进而提升服务质量。关于TPU未来能否完全取代CPU和GPU在神经网络计算中的地位,您有何看法?欢迎点赞、分享本文,并在评论区展开讨论。
比特派钱包2025官网下载:bit114.app,bit115.app,btp1.app,btp2.app,btp3.app,btbtptptpie.tu5223.cn,tokenim.app,bitp2.app